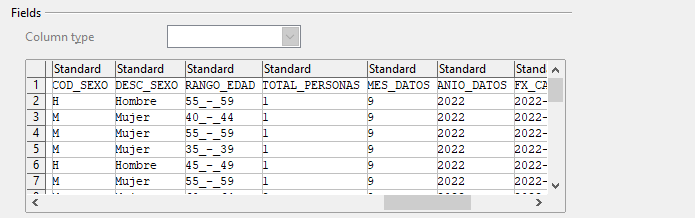
Para este ejercicio se ha utlizado un ejemplo de datos de RRHH de la Comunidad de Madrid, descargado del siguiente enlace «https://datos.madrid.es/egob/catalogo/300584-12-rrhh_efectivos_ult_periodo.csv«
Importamos las librerias:
import os
import pandas as pdcon os.mkdir creamos el directorio:
os.mkdir('data/Datos_distrito')Listamos la carpeta de origen de datos:
os.listdir('data')
['Datos_distrito', 'rrhh202210.csv']Creamos dos DF, uno con la lectura del CSV de origen de datos y otro con la seleccion de datos del Distrito Centro:
# Load the data into a DataFrame
datos_df = pd.read_csv('data/rrhh202210.csv')
# Select only data for the year 2002
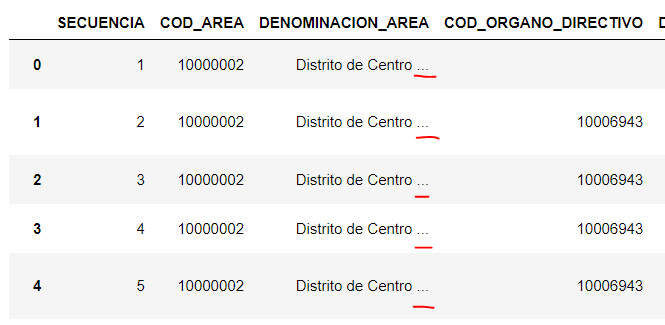
DistritoCentro = DistritoCentro = datos_df[datos_df.DENOMINACION_AREA == 'Distrito de Centro ']
DistritoCentroDebido a que los datos del campo DENOMINACION_AREA tienen un espacio posterior, debemos contar con ese espacio para que el comando anterior funcione correctamente:
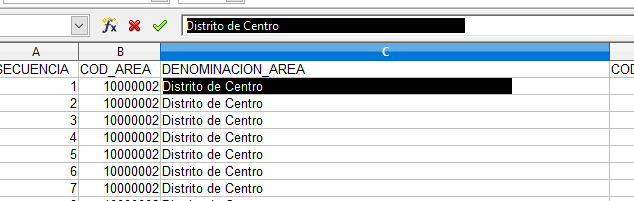
Para solventar el problema de esta columna y eliminar el espacio en el string, ejecutamos el siguiente comando (este comando elimina los espacios anteriores y posteriores de una columna):
datos_df['DENOMINACION_AREA'] = datos_df['DENOMINACION_AREA'].str.strip()
datos_dfAhora ya podemos ejecutar el comando anterior, sin el espacio en el string
DistritoCentro = datos_df[datos_df.DENOMINACION_AREA == 'Distrito de Centro']
DistritoCentro
exportamos los datos a un CSV:
# Write the new DataFrame to a CSV file
DistritoCentro.to_csv('data/Datos_distrito/DistritoCentro.csv')Para no realizar esta tarea repetitiva, distrito por distrito, podemos crear un loop que recorra los denominaciones de area y genere los ficheros.
Listamos la columna «DENOMINACION_AREA» con el parametro «unique», para que solo nos muestre nombres unicos:
datos_df['DENOMINACION_AREA'].unique()
Probamos toda esta informacion en un loop:
for DENOMINACION_AREA in datos_df['DENOMINACION_AREA'].unique():
filename='data/Datos_distrito/Distrito' +'_'+ str(DENOMINACION_AREA) + '.csv'
print(filename)
Todo parece funcionar de forma correcta, pero antes de crear el loop y dividir la informacion por distritos, debemos realizar algunas modificaciones en los datos, ya que contienen valores nulos y mas espacios en blanco que arruinarian nuestra salida, por ello comenzaremos de nuevo con todo el origen de datos.
Importamos los datos:
datos_df_raw = pd.read_csv('data/rrhh202210.csv', on_bad_lines='skip', sep=";")
datos_df_rawEliminamos los valores nulos de todo el DF:
datos_df=datos_df_raw.dropna()
datos_df
Borramos todos los espacios delante y detras de todos los string, para ello creamos una funcion que haga un loop y recorra todos los string, eliminando los espacios delante y detras:
def space_remover(dataframe):
# iterating over the columns
for i in dataframe.columns:
# checking datatype of each columns
if dataframe[i].dtype == 'object':
# applying strip function on column
dataframe[i] = dataframe[i].map(str.strip)
else:
# if condn. is False then it will do nothing.
pass
# applying whitespace_remover function on dataframe
space_remover(datos_df)
# printing dataframe
datos_df
A continuacion remplazamos todos los espacios en banco por _, en todo el DF, dado que es necesario para que el ultimo paso se ejecute de forma correcta (los espacios en blanco causan muchos problemas con la libreria Pandas, siempre es mejor eliminarlos):
datos_df=datos_df.replace({" ": "_"}, regex=True)
datos_df
añadimos el resto de pasos para crear los ficheros con la informacion por distritos:
for DENOMINACION_AREA in datos_df['DENOMINACION_AREA'].unique():
# Select data for the distrito
datos_area = datos_df[datos_df.DENOMINACION_AREA == DENOMINACION_AREA]
# Write the new DataFrame to a CSV file
filename = 'data/Datos_distrito/Distrito' + str(DENOMINACION_AREA) + '.csv'
datos_area.to_csv(filename)como podemos ver se han creado lo ficheros CSV:
Y comprobamos que se ha realizado la division de forma correcta: